Cassandra Installations on Windows Machine
Prior to installations set up Java in windows and set environment paths as well
Step 1)
Download Cassandra tar file in your windows machine of any location
Click below link to download tar file
If u want new version of Cassandra click on the latest version or else check the version in Cassandra archives (check this section of above URL -> Previous and Archived Cassandra Server Releases)
Click on the tar file. It will download into your windows machine

Step 2)
Go to Download tar file location and extract files using (WinZip or 7zip)
Copy the extracted file into your any drive. In my Case I am placing it in ‘D :/< location>’
Location means your Cassandra extracted file
Step 3)
Set up Cassandra home path in environment variables (see the below screen shot to set path in environment variables)
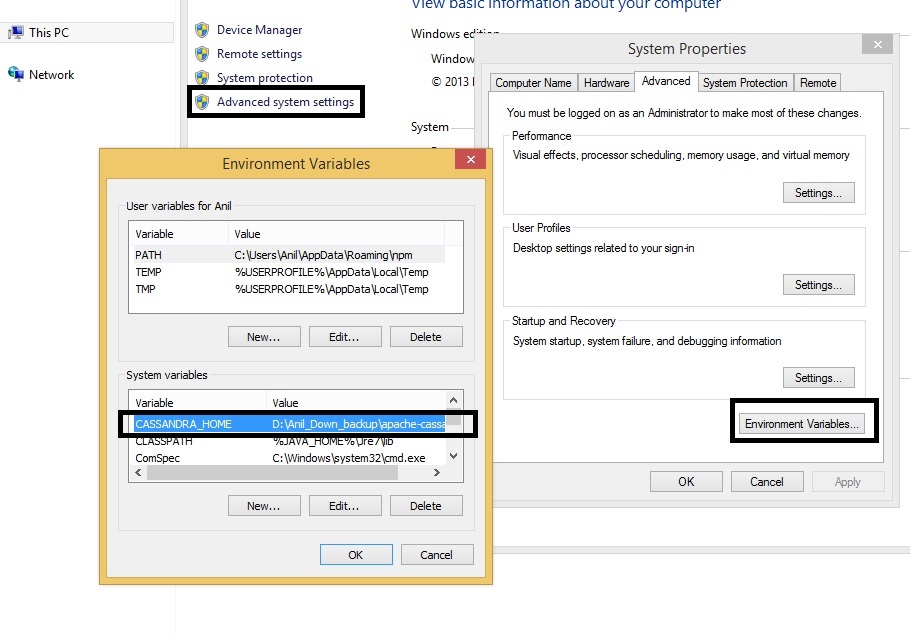 |
CASSANDRA_HOME=D :\< location of Cassandra>
Step 4)
Go to Cassandra.yaml file and search for this line ( Commitlog_Directory and data_file_directories)
CommitLogDirectory: /var/lib/cassandra/commitlog
And change the line into
CommitLogDirectory: D :/< location of Cassandra/commitlog
Create commit log folder in the specified location (As mentioned above)
data_file_directories : /var/lib/Cassandra/Data
and change the line to
data_file_directories: D :/< location of Cassandra/data
Create data folder in the specified location (As mentioned above)
See Screenshot below for better understanding

Step 5)
Once the above 4 steps are done as mentioned above
Go to command prompt in windows -> then switch to Cassandra folder location -> run the Cassandra instance by entering Cassandra.bat command
Then enter
Cassandra-cli.bat in another terminal to interact with Cassandra
See Screenshot for better understanding

So once everything is working fine it means that installations done properly








